
Docker Network - Container Networking Model
Container Networking Model
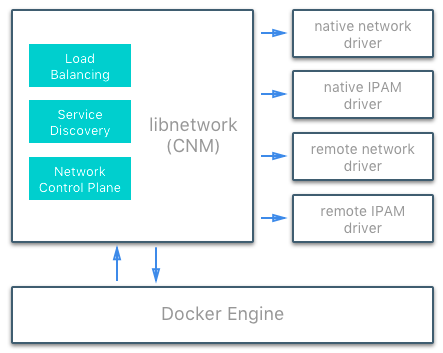
Docker networking architecture は Container Networking Model (CNM) と呼ばれるインターフェースの集まりで構成される。
CNM の思想としては様々なインフラストラクチャをまたいでアプリケーションのポータビリティを提供することである。
CNM Constructs
CNM にはいくつかのハイレベルな構造が存在している。それらは OS やインフラストラクチャに依存せず、アプリケーションはインフラストラクチャスタックに関係なく統一的に操作を行える。
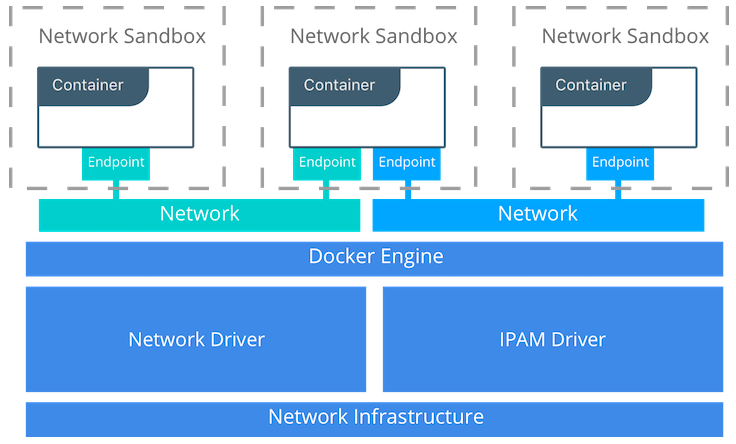
Sandbox
Sandbox はコンテナのネットワークスタックの設定を持つもの。これにはコンテナのインターフェース, ルーティングテーブル, DNS 設定などが含まれる。
Sandbox の実装は Linux Namespace や FreeBSD Jail, またはそれに似たような概念で実現される。
一つの Sandbox は複数ネットワークからの多数の endpoints を持つ。
Endpoint
Endpoint は Sandbox を Network に参加させるためのもの。
Endpoint が存在するので、ネットワークへの実際の接続はアプリケーションから見て抽象化することができる。
これによりメンテナンスの手軽さが実現され、またサービスは異なる種類の network driver を「どのようにネットワークに接続されるか」ということを気にすることなく利用できる。
Network
CNM の Network は OSI 参照モデルに依存しないようなものである。
Network の実装は Linux bridge や VLAN などにより実現される。
Network は、互いに疎通性を持つような endpoints の集まりである。 Network に接続されていない endpoint は Network への疎通性を持たない。
以下、参考図。([1]より)
CNM Driver Interfaces
CNM は、ユーザやコミュニティ、またはベンダーから利用可能な 2 種の pluggable で open なインターフェースを、機能性の拡張や可視化、ならびにネットワークの操作のために提供している。
Network Drivers
Docker Network Drivers は、実際にネットワークが動作するための実装を提供する。
これらは pluggable なので簡単に利用および交換可能で、様々なユースケースをカバーする。
複数の Network Drivers が既存の Docker Engine や Cluster concurrently で使われうる。しかし、それぞれの Docker network は単体の Network Driver を介してのみインスタンス化される。
以下、 2 種の CNM network drivers が存在する。 -> 詳細は 02 にて
・Native Network Drivers
Docker Engine ネイティブな仕組みであり、 Docker により提供される。
複数の種類存在しており、ユースケースによって使い分け可能。
・Remote Network Drivers
コミュニティや他のベンダにより提供されるもの。
これらの driver はソフトウェアやハードウェアと連携するのに必要な機能を提供する場合がある。
また、ユーザも独自の driver を作成することができる。
IPAM Drivers
Docker はネイティブの IP Address Management Driver を持っている。これは、ネットワークやエンドポイントが指定されていない場合にデフォルトのサブネットや IP アドレスを提供するもの。
IP アドレスの指定は、 network, container, および service を作成するコマンドを介してもアサインが可能。
Remote IPAM driver も存在しており、既存の IPAM tool と連携する機能を提供する。
(Remote IPAM driver の例: infoblox)
以下、参考図。([1]より)
Docker Network Control Plane
Docker 上に広がるネットワークは、コントロールプレーンの propagation に加えて Swarm-scoped Docker network を管理する。
これは Docker Swarm cluster にビルトインの機能であり、外部の Key Value Store のような外的なコンポーネントを必要としない。
コントロールプレーンはネットワークの状態についての情報や各クラスタをまたがるトポロジを管理するために Gossip protocol を利用している。 Gossip protocol は、非常に大規模なクラスタでも一定の割合のメッセージサイズ、障害検出時間、および収束時間を維持しながら、クラスタ内で結果整合性を維持するのに非常に効果的である。これにより、収束に時間がかかったり、ノードの誤検知などのスケーリング時の問題を発生させることなく、ネットワークが多数のノードにわたってスケールできるようになる。
コントロールプレーンは、非常にセキュアで、信頼性が高く、暗号化チャネルによる認証を持つ。また、これらはネットワークごとにスコープ化されており、特定のホストが受信するアップデートが大幅に減少する。
以下、参考図。([1]より)
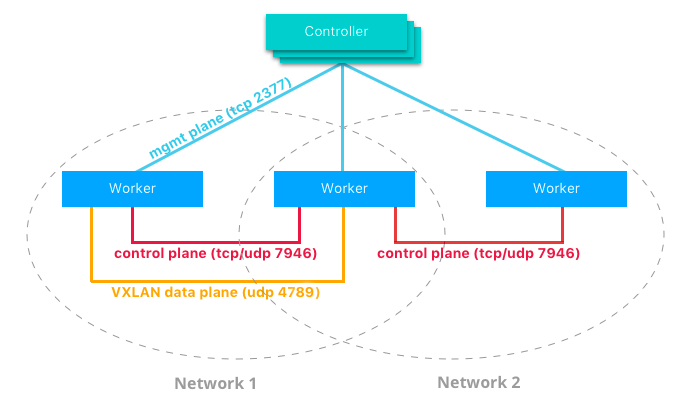
複数のコンポーネントにより構成されており、大規模なネットワークにおいても短時間で収束させるために各コンポーネントは相互的に動作している。この分散的な仕組みにより、クラスタコントローラの障害がネットワークパフォーマンスに影響を与えないことを保証している。
Docker network control plane のコンポーネントは以下のとおりである。
Message Dissemination
それぞれが情報をより大きなノードグループと情報交換をして情報を広げるかたちで、 Peer to Peer でノードを更新する仕組み。
インターバルと Peer グループサイズが固定されることで、クラスタがスケールしてもネットワーク使用量は一定となることを保証する。
Peer をまたいで指数関数的に情報を propagate することで、収束が高速でどのようなクラスタサイズであっても結び付けられることを保証する。
Failure Detection
直接的または間接的に Hello メッセージを送ることで、ネットワークの輻輳やノード障害の誤検知を排除する。
Full State Syncs
定期的に Full State Syncs を実施することで、すばやく一貫性を実現し、ネットワークの隔離を解決する。
Topology Aware
Topology Aware アルゴリズムは、 Peer 同士などの相対的なレイテンシを把握している。
これは Peer グループがより高速で効率的に収束できることを最適化している。
Control Plane Encryption
man in the middle やその他のネットワークセキュリティを脅かす攻撃から防御している。